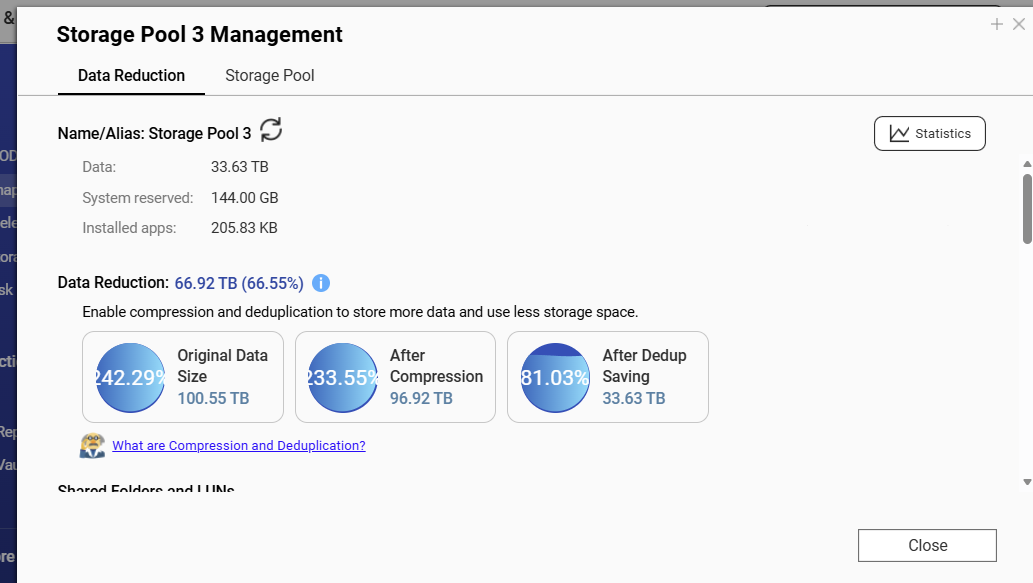
verwendet wird: Quts auf einem TVS-1288x, 128 GB RAM, ein RAID6 Storage-Pool mit 8x8TB Festplatten
Auf diesem Volume gibt es eine hohe Deduplizierungsrate.
Die Originaldaten wachsen um ca. 1 TB pro Monat.
Im Verlauf der letzten Monate nimmt die Performance auf deduplizierten Ordnern dramatisch ab.
NICHT deduplizierte Ordner funktionieren normal.
Ich habe den Verdacht, dass der nutzbare RAM an seine Grenzen stößt.
Daher nimmt die Deduplizierungs-Performance ab.
Gibt es eine Möglichkeit zu prüfen, ob der Deduplizierungsprozess keinen physischen RAM mehr zur Verfügung hat?
Zusätzlich: Wie kann man den Status von ZFS bezüglich des verwendeten Speichers überprüfen?
Bei einem QNAP-Support-Ticket habe ich nachgefragt, aber die Antwort war: „Sie wissen es nicht.“
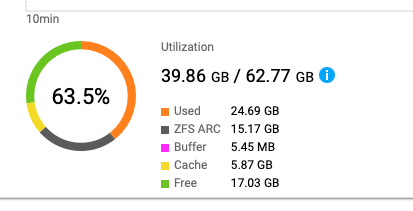
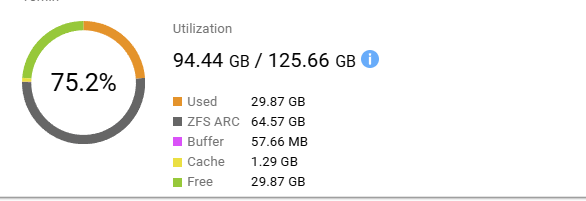
Du kannst den Ressourcenmonitor öffnen und die Speicherauslastung ansehen. Es gibt einen Eintrag für ZFS ARC, aber ich bin mir nicht sicher, ob das der Speicher ist, der für die Deduplizierung verwendet wird.
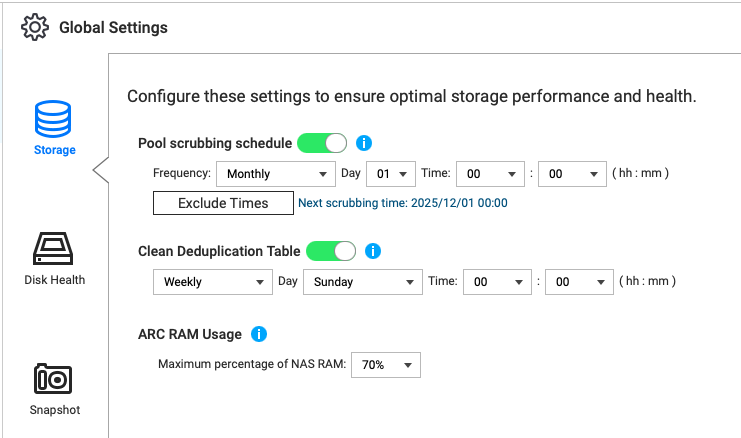
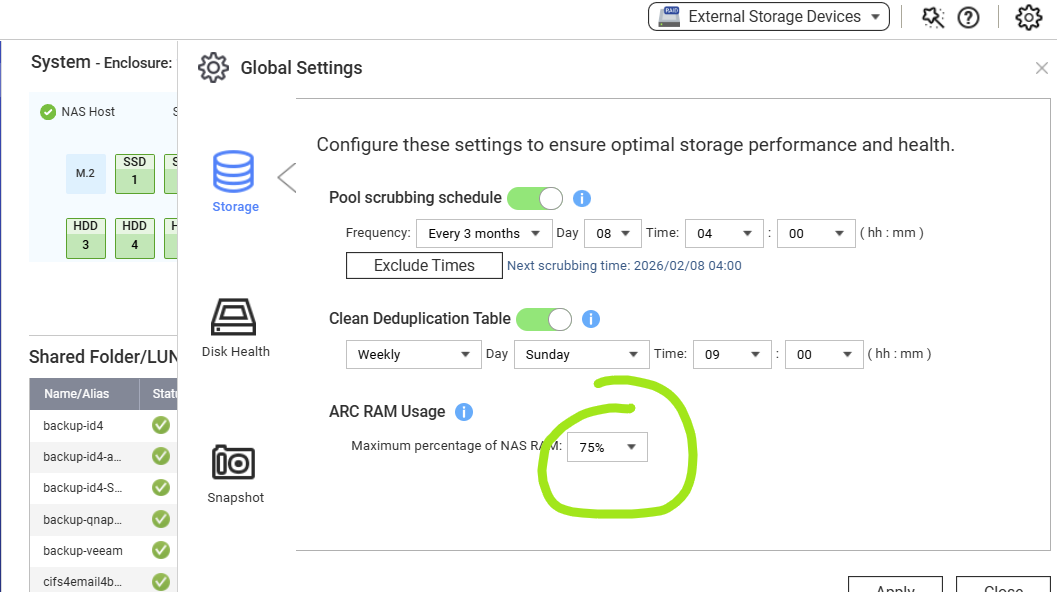
Es kann hilfreich sein zu sehen, wie viel Speicher du verwendest, und du kannst die Menge des Speichers, den ARC verwendet, unter Speicher und Snapshots ändern. Welcher Wert ist bei dir eingestellt? Kannst du ihn erhöhen?
Wenn du die Größe erhöhst, würde ich erwarten, dass die Deduplizierung abnehmen könnte, da die Frage ist, wie viel von diesen neuen Daten tatsächlich doppelte Daten sind.
Die ARC-RAM-Nutzung ist auf den höchstmöglichen Wert eingestellt.
Arc hat also noch Speicher, den es sich selbst zuweisen kann.
Das Problem mit dem Support ist, dass solche kniffligen Detailfragen echt mühsam sind.
Bei diesem Performance-Problem bin ich mit ihnen nicht weit gekommen.
OK. Gut. Ich bin kein Experte für Deduplizierung und bin mir auch nicht zu 100 % sicher, ob der für ZFS ARC zugewiesene Speicher für die Inline-Komprimierung und Deduplizierung verwendet wird. Ich würde „annehmen“, dass das der Fall ist, aber du weißt ja, was passiert, wenn man „an-nimmt“!
Aber wie gesagt, ich würde erwarten, dass die Effizienz der Deduplizierung sinkt, je größer dein Dateispeicher wird. Ich gehe davon aus, dass die statistische Wahrscheinlichkeit, dass Dateien die gleichen Daten enthalten, mit zunehmender Dateianzahl abnimmt. Und selbst in Fällen, in denen du sehr ähnliche Daten hast, nehme ich an, dass jede Datei neben den „gleichen“ Daten auch leicht unterschiedliche Daten enthält. Ich würde nicht erwarten, dass alle deine Dateien exakte Duplikate voneinander sind (vielleicht sind sie es, aber das wäre ungewöhnlich). Daher wird dein nicht duplizierter Datenbestand wachsen, und je mehr er wächst, desto kleiner wird der Anteil der duplizierten Daten am Gesamtvolumen.