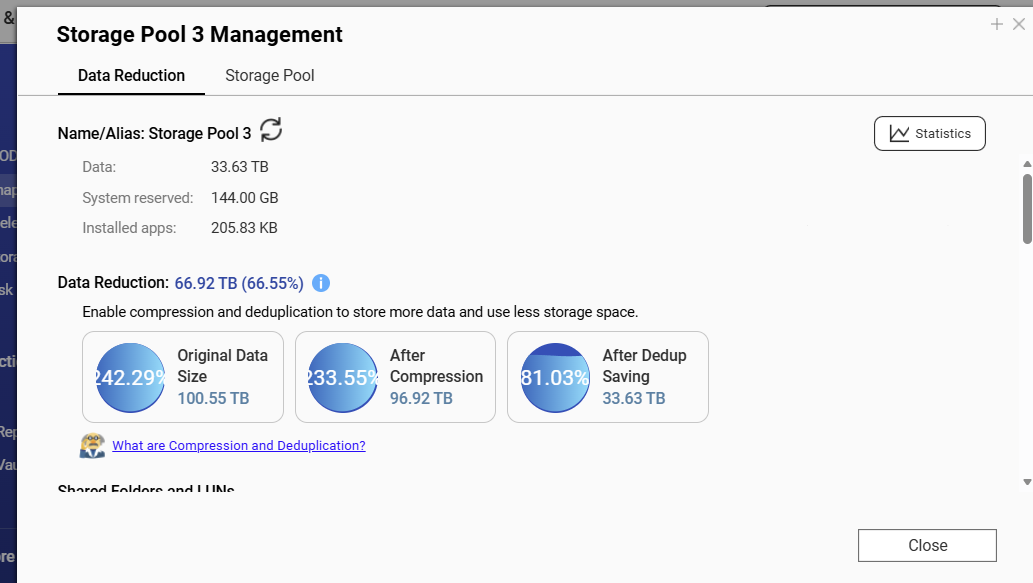
menggunakan: Quts pada tvs-1288x, RAM 128GB, satu storage pool RAID6 dengan 8x8TB Disk
pada volume ini, terdapat tingkat deduplikasi yang tinggi.
Data asli meningkat sekitar 1 TB setiap bulan
Dalam beberapa bulan terakhir, performa pada folder yang dideduplikasi menurun drastis.
Folder yang TIDAK dideduplikasi masih berperforma normal.
Saya menduga jumlah RAM yang dapat digunakan telah mencapai batasnya.
Oleh karena itu, performa deduplikasi menurun.
Apakah ada cara untuk memeriksa apakah deduplikasi kehabisan RAM fisik?
Selain itu, bagaimana cara memeriksa status ZFS terkait penggunaan memori?
Saya sudah membuat tiket dukungan ke QNAP, tapi jawabannya “mereka tidak tahu”
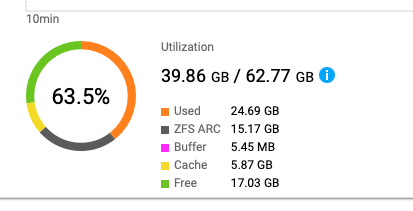
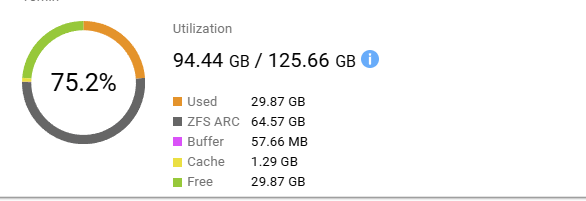
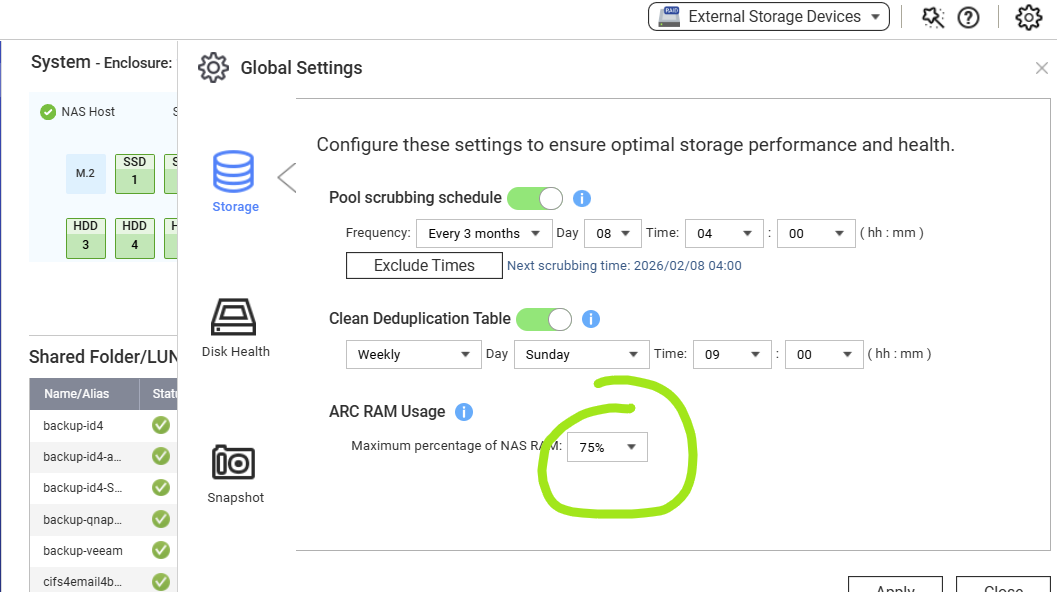
Anda dapat membuka Resource Monitor dan melihat penggunaan Memori. Ada item untuk ZFS ARC, tetapi saya tidak yakin apakah itu adalah memori yang digunakan untuk De-duplication (deduplikasi).
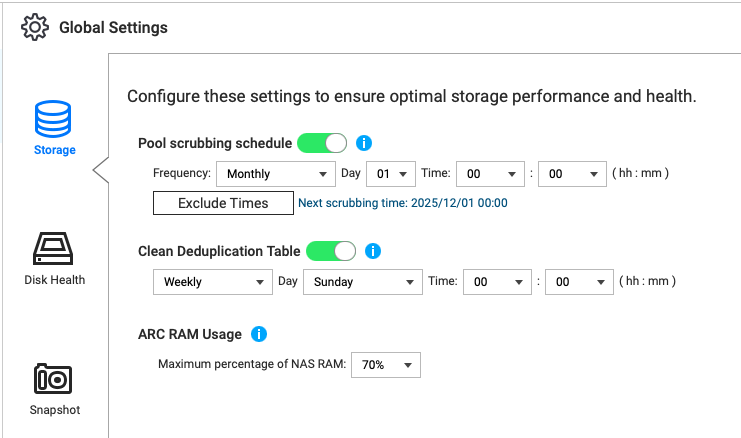
Mungkin akan membantu untuk melihat berapa banyak memori yang Anda gunakan dan Anda dapat mengubah jumlah memori yang digunakan ARC di Storage and Snapshots (Penyimpanan dan Snapshot). Level berapa yang disetel pada milik Anda? Bisakah Anda meningkatkannya?
Saat Anda meningkatkan ukuran, saya memperkirakan deduplikasi bisa berkurang karena seberapa banyak dari konten data baru tersebut adalah data duplikat?
Penggunaan RAM ARC diatur ke jumlah tertinggi yang tersedia.
Jadi Arc masih memiliki memori yang bisa dialokasikan untuk dirinya sendiri.
Sayangnya, untuk dukungan, masalah-masalah detail yang rumit seperti ini memang merepotkan.
Saya tidak mendapatkan banyak bantuan dari mereka terkait masalah performa ini.
OK. Bagus. Saya bukan ahli dalam deduplikasi dan saya juga tidak 100% yakin bahwa memori yang dialokasikan untuk ZFS ARC digunakan untuk kompresi dan deduplikasi secara langsung. Saya “mengasumsikan” bahwa memang demikian, tapi Anda tahu apa yang terjadi jika kita “meng-a-su-me”!
Namun seperti yang saya katakan, saya memperkirakan efisiensi deduplikasi akan menurun seiring bertambahnya ruang file Anda. Saya memperkirakan kemungkinan statistik file yang memiliki data sama akan semakin kecil ketika jumlah file Anda bertambah. Bahkan dalam kasus di mana Anda memiliki data yang sangat mirip, asumsi saya adalah setiap file akan memiliki sedikit perbedaan data selain data yang “sama”. Saya tidak berharap semua file Anda benar-benar duplikat satu sama lain (mungkin memang begitu, tapi itu akan aneh). Jadi data yang tidak terduplikasi akan bertambah, dan seiring pertumbuhannya, data yang terduplikasi akan menjadi persentase yang semakin kecil dari total keseluruhan.