Hallo zusammen,
ich versuche, Ollama mit GPU-Beschleunigung innerhalb von Docker auf meinem QNAP NAS auszuführen, aber es fällt immer auf die CPU zurück. Ich habe schon einiges an Debugging betrieben und würde mich über jeden Rat oder eine Bestätigung freuen, ob dies eine bekannte Einschränkung ist.
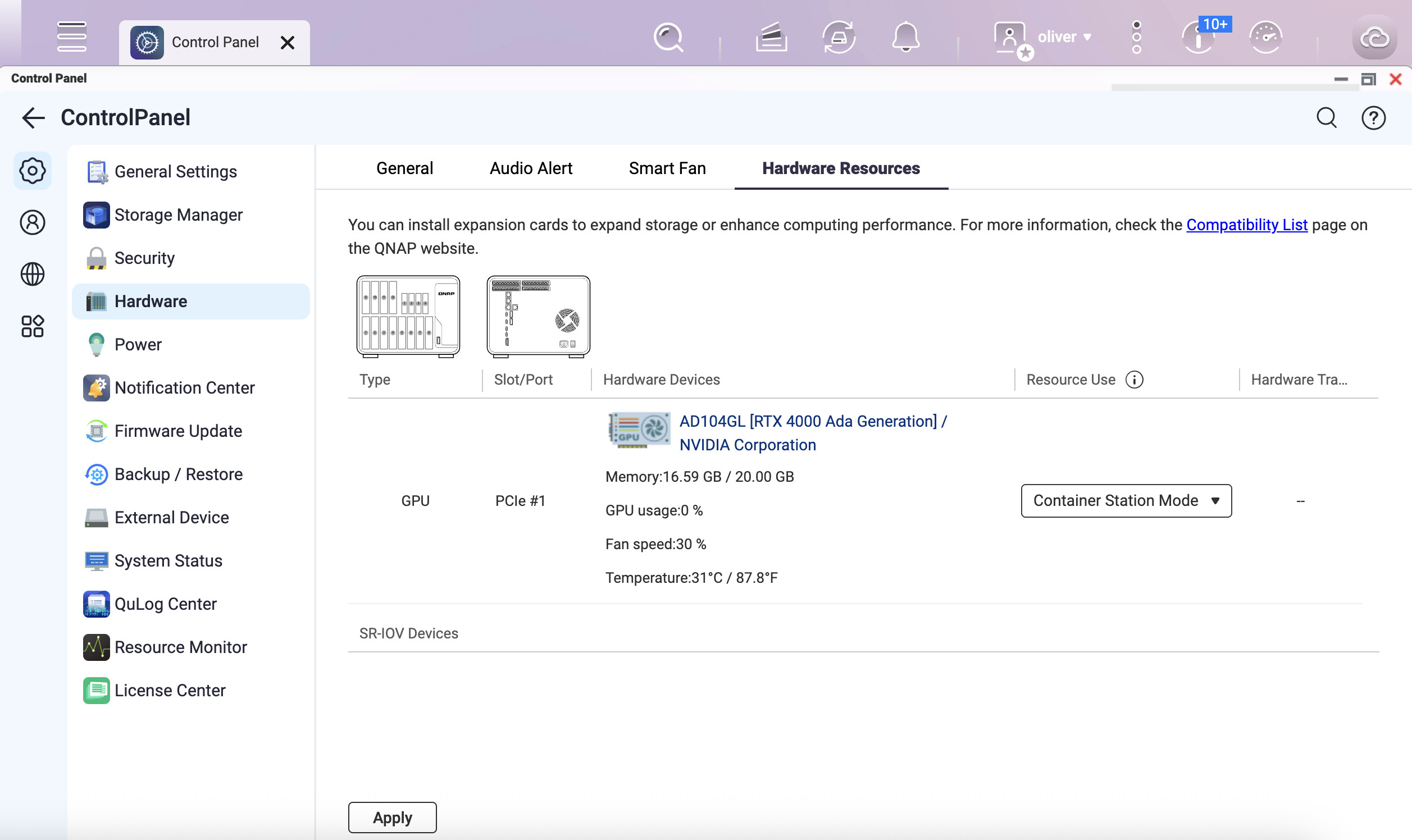
 Mein Setup
Mein Setup
-
QTS: 5.2.9
-
Kernel: 5.10.60-qnap
-
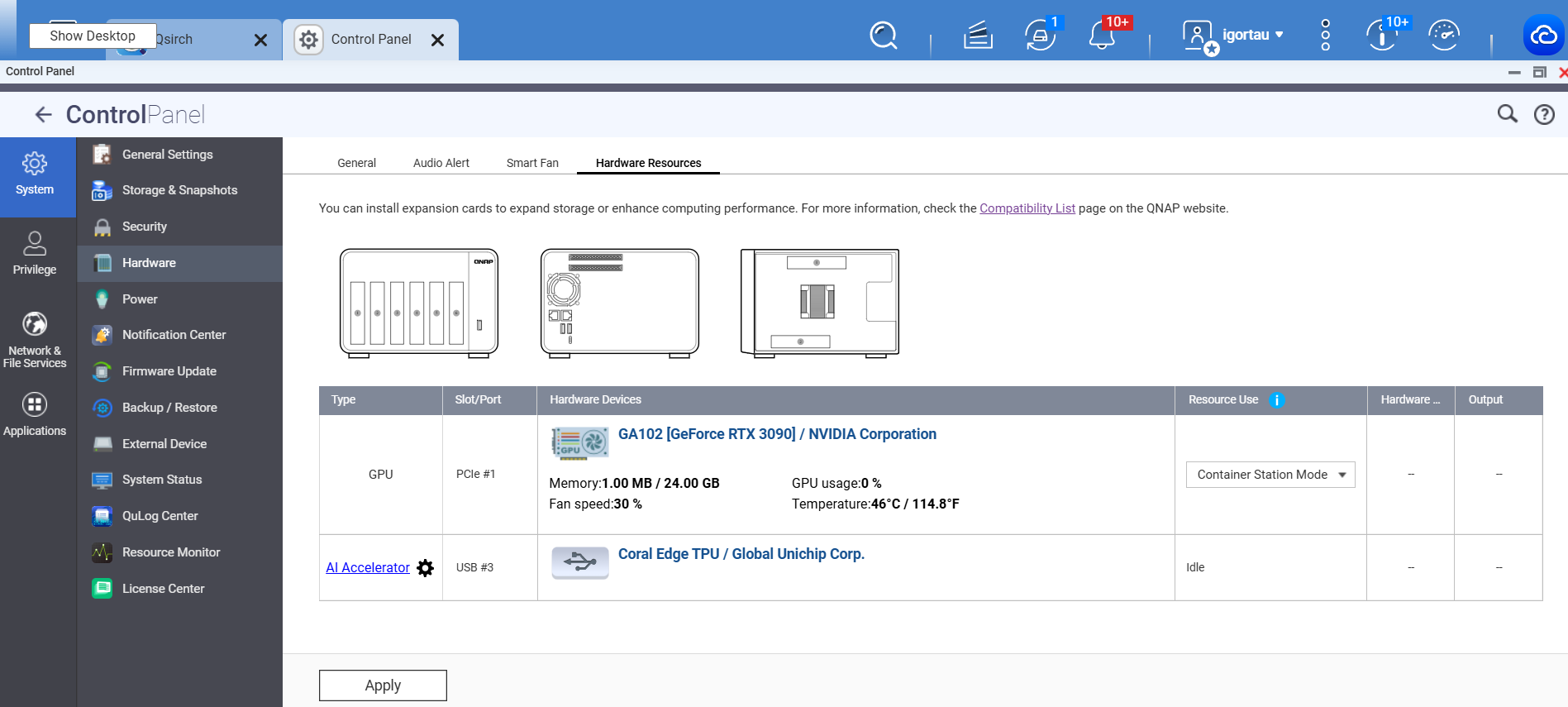
GPU: NVIDIA GeForce RTX 3090
-
NVIDIA-Treiber (QPKG): 575.64.05
-
Treibertyp: NVIDIA Open Kernel Module
-
Docker: Container Station + CLI (
--gpus all)
 Was funktioniert
Was funktioniert
-
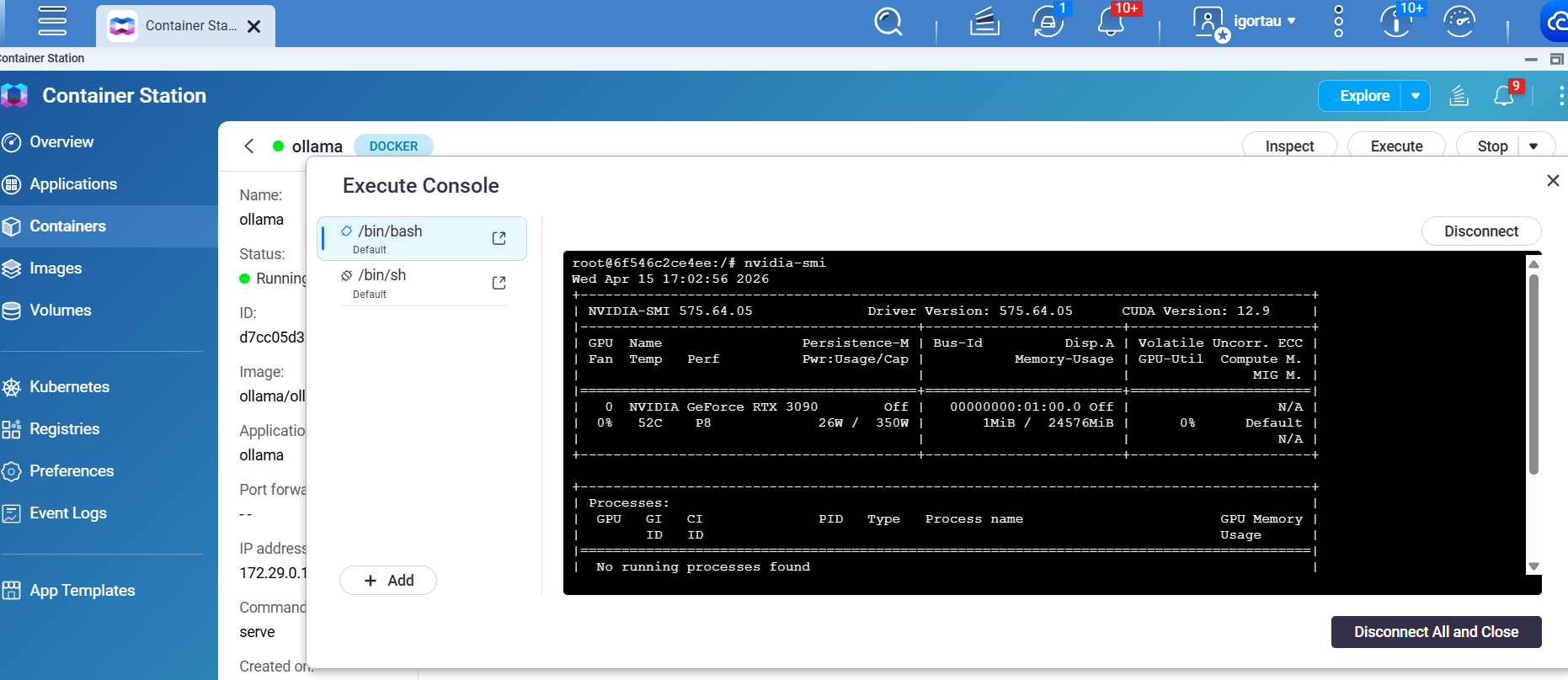
nvidia-smifunktioniert auf dem Host (über Container) -
nvidia-smifunktioniert innerhalb von Containern -
/dev/nvidia*Geräte sind vorhanden -
NVIDIA-Module geladen:
nvidia
nvidia_uvm
nvidia_modeset
nvidia_drm
GPU-Passthrough zu Containern scheint also zu funktionieren.
 Was NICHT funktioniert
Was NICHT funktioniert
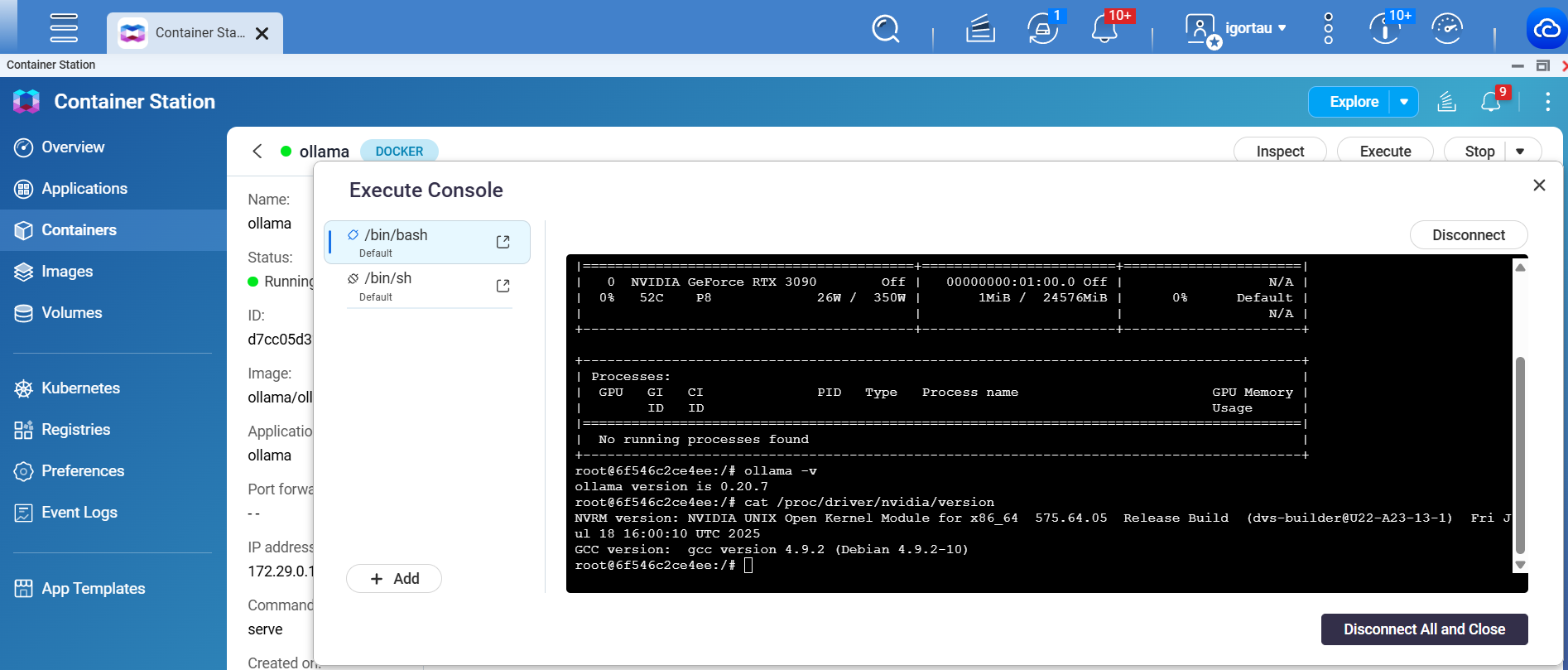
Ollama erkennt die GPU nicht und nutzt immer die CPU:
inference compute id=cpu library=cpu
total_vram="0 B"
Obwohl die GPU verfügbar ist.
 Was ich getestet habe
Was ich getestet habe
1. Verschiedene Ollama-Versionen
-
0.20.6-rc1
-
0.20.5
-
0.19.0
→ gleiches Ergebnis (nur CPU)
2. CUDA-Bibliotheken
Innerhalb des Containers sind CUDA-Bibliotheken vorhanden:
/usr/lib/ollama/cuda_v12/libcudart.so.12
/usr/lib/ollama/cuda_v12/libcublas.so.12
/usr/lib/ollama/cuda_v12/libcublasLt.so.12
Anfangs zeigte ldd fehlende Bibliotheken, aber nach Setzen von:
LD_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/cuda_v12:/usr/lib/x86_64-linux-gnu
→ alle Abhängigkeiten werden korrekt aufgelöst.
3. Scheitert trotzdem
Trotzdem schlägt die CUDA-Initialisierung in Ollama fehl:
ggml_cuda_init: failed to initialize CUDA: initialization error
4. Kernel-Logs (das sieht verdächtig aus)
NVRM: nvCheckOkFailedNoLog: Check failed: Out of memory [NV_ERR_NO_MEMORY]
NVRM: faultbufCtrlCmdMmuFaultBufferRegisterNonReplayBuf_IMPL: Error allocating client shadow fault buffer
 Mein aktueller Stand
Mein aktueller Stand
Es sieht so aus, als ob:
-
GPU-Passthrough funktioniert (Docker-Seite OK)
-
CUDA-Bibliotheken sind vorhanden
-
aber CUDA-Initialisierung zur Laufzeit fehlschlägt
Da ich das NVIDIA Open Kernel Module verwende, vermute ich:
![]() es unterstützt in dieser Umgebung möglicherweise keine CUDA-Workloads vollständig
es unterstützt in dieser Umgebung möglicherweise keine CUDA-Workloads vollständig
![]() oder es gibt ein Kompatibilitätsproblem mit dem QNAP-Kernel (5.10.60)
oder es gibt ein Kompatibilitätsproblem mit dem QNAP-Kernel (5.10.60)
 Fragen
Fragen
-
Hat jemand erfolgreich Ollama (oder eine andere CUDA-intensive App) mit GPU auf QNAP ausgeführt?
-
Ist das eine bekannte Einschränkung des NVIDIA Open Kernel Module auf QNAP?
-
Ist es möglich, den proprietären NVIDIA-Treiber statt des Open Modules zu verwenden?
-
Hat jemand solche
NV_ERR_NO_MEMORY-Fehler schon einmal gesehen?
 Workaround
Workaround
Aktuell überlege ich:
-
Ollama auf einer separaten Linux-Maschine (Debian/Ubuntu) laufen zu lassen
-
und QNAP nur für UI/Services zu verwenden