みなさんこんにちは、
OllamaをQNAP NAS上のDocker内でGPUアクセラレーション付きで実行しようとしていますが、常にCPUにフォールバックしてしまいます。かなりデバッグを行いましたので、何かアドバイスや、これが既知の制限かどうかご存知の方がいれば教えていただきたいです。
QTS: 5.2.9
カーネル: 5.10.60-qnap
GPU: NVIDIA GeForce RTX 3090
NVIDIAドライバ(QPKG): 575.64.05
ドライバタイプ: NVIDIA Open Kernel Module
Docker: Container Station + CLI(--gpus all)
nvidia
nvidia_uvm
nvidia_modeset
nvidia_drm
このため、GPUのコンテナへのパススルー自体は問題なさそうです。
OllamaがGPUを検出せず、常にCPUを使用します:
inference compute id=cpu library=cpu
total_vram="0 B"
GPUは利用可能なはずなのに。
0.20.6-rc1
0.20.5
0.19.0
→ いずれも同じ結果(CPUのみ)
コンテナ内にCUDAライブラリは存在します:
/usr/lib/ollama/cuda_v12/libcudart.so.12
/usr/lib/ollama/cuda_v12/libcublas.so.12
/usr/lib/ollama/cuda_v12/libcublasLt.so.12
最初はlddでライブラリ不足が出ていましたが、以下を設定後:
LD_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/cuda_v12:/usr/lib/x86_64-linux-gnu
→ すべての依存関係が正しく解決されました。
それにもかかわらず、OllamaはCUDA初期化に失敗します:
ggml_cuda_init: failed to initialize CUDA: initialization error
NVRM: nvCheckOkFailedNoLog: Check failed: Out of memory [NV_ERR_NO_MEMORY]
NVRM: faultbufCtrlCmdMmuFaultBufferRegisterNonReplayBuf_IMPL: Error allocating client shadow fault buffer
どうやら:
自分はNVIDIA Open Kernel Module を使っているので、
**Ollama(またはCUDAを多用するアプリ)**をQNAPでGPU動作させた方はいますか?
NVIDIA Open Kernel Module on QNAP の既知の制限でしょうか?
オープンモジュールの代わりにプロプライエタリNVIDIAドライバ を使うことは可能ですか?
このようなNV_ERR_NO_MEMORYエラーを見たことがある方はいますか?
現時点では、
ことを検討しています。
marcoi
2026 年 4 月 12 日午後 6:07
2
docker composeファイルを使用している場合は、ollamaセクションに以下を追加してください。
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
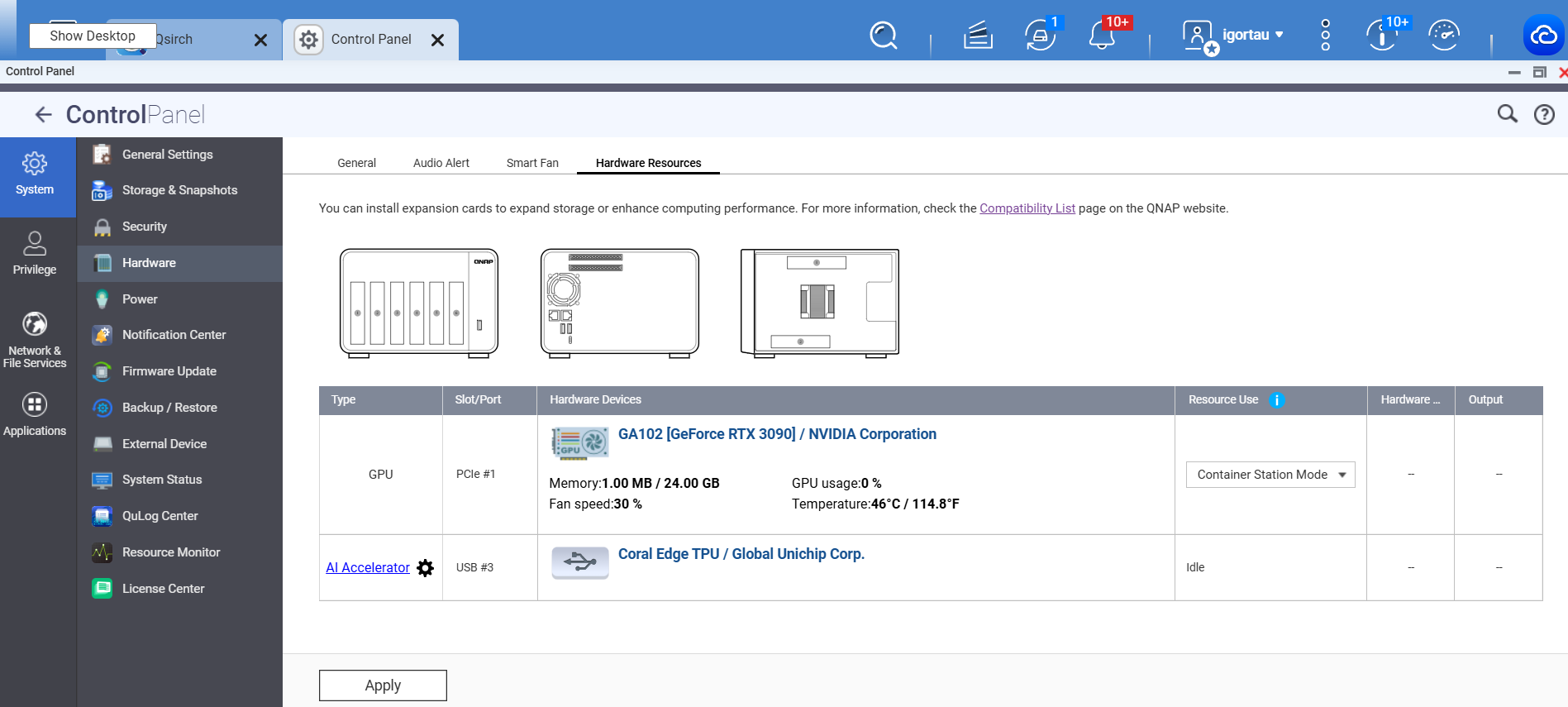
こんにちは、「Docker:Container Station + CLI」とはどういう意味ですか?
nvidia-smiはホスト上(コンテナ経由)で動作します
===
問題を確認するために、以下の手順に従ってください:
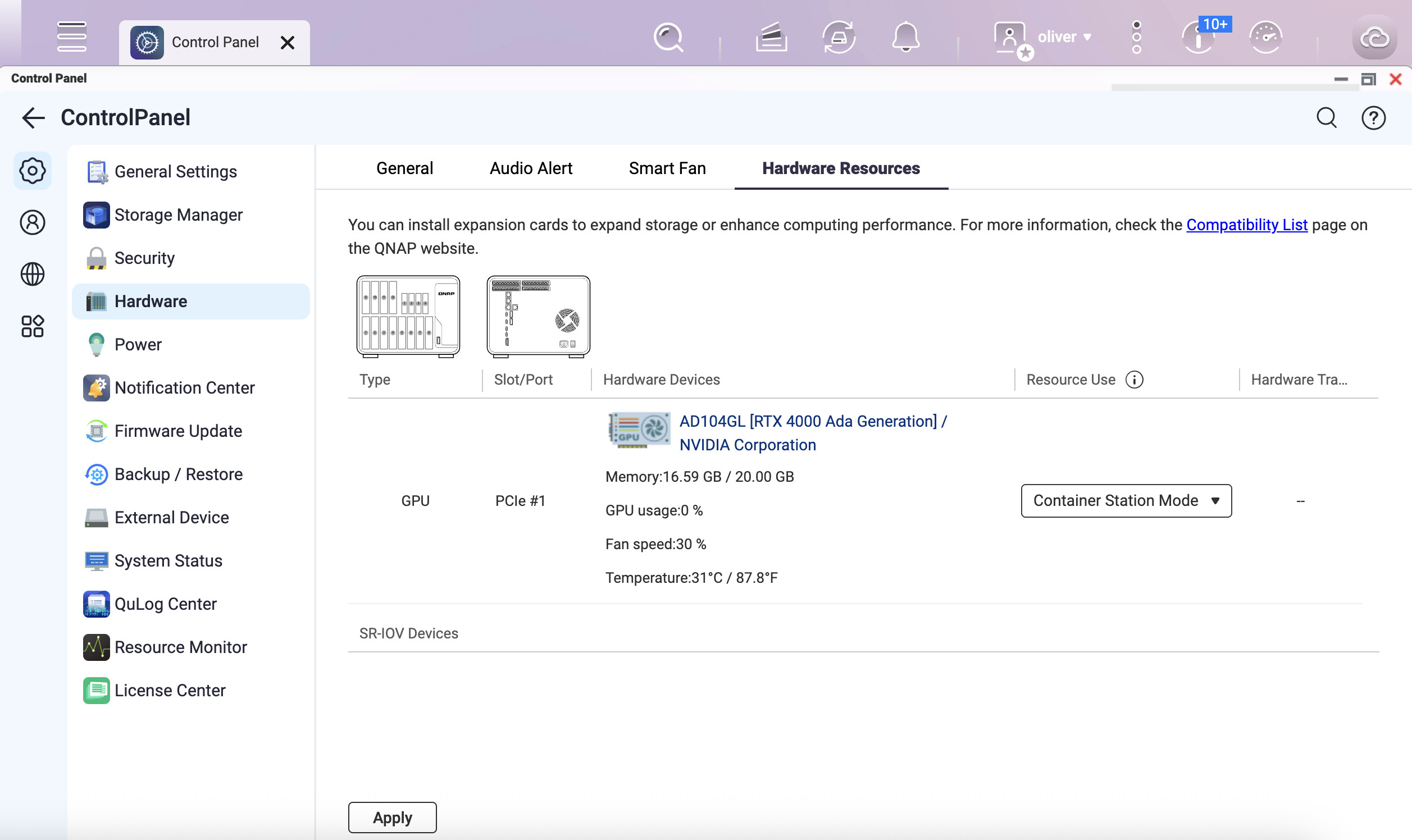
コントロールパネルでGPU設定をキャプチャしてください。
このYAMLファイルを使用して、Container Stationで新しいアプリケーションを作成してください。
services:
ollama:
image: ollama/ollama:latest
volumes:
- ollama:/root/.ollama
restart: unless-stopped
environment:
- OLLAMA_SCHED_SPREAD=1
ports:
- 11434:11434
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
ollama:
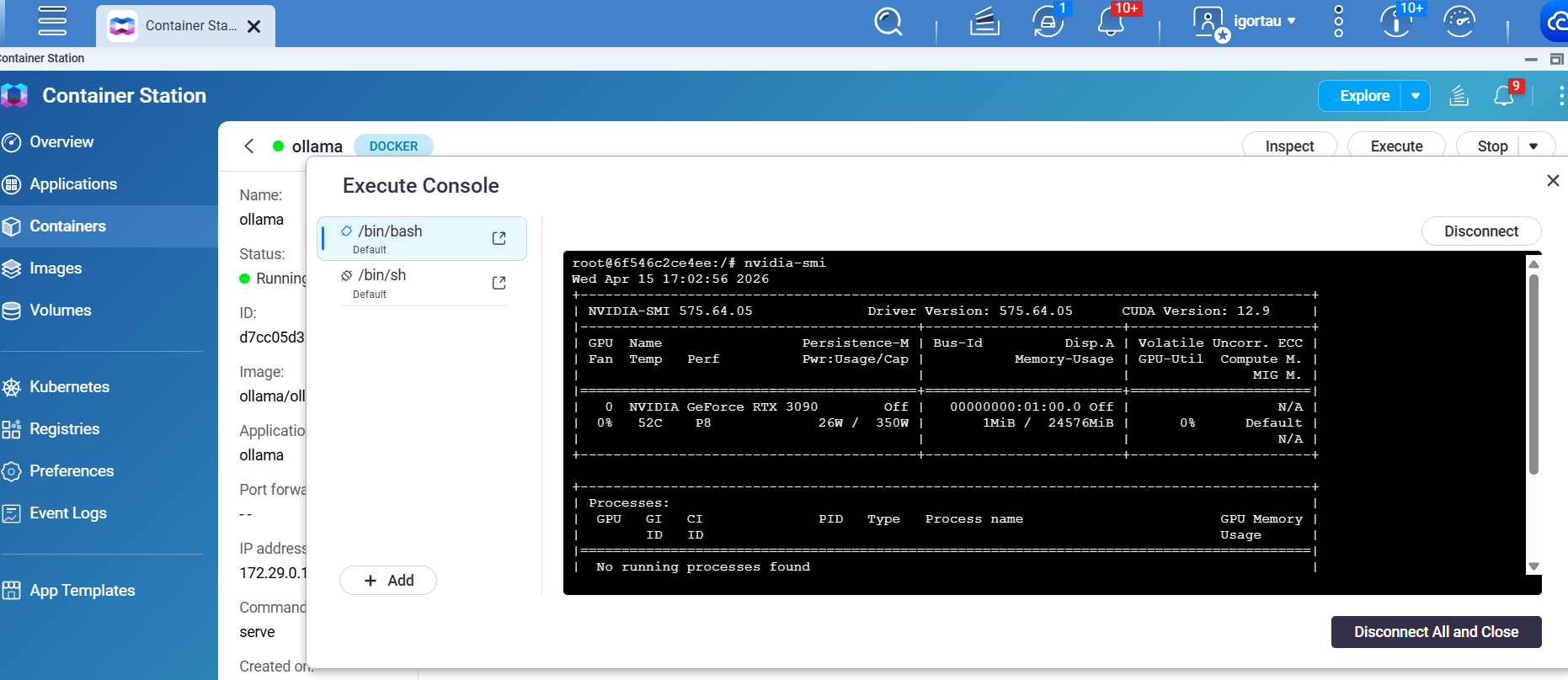
新しく作成したOllamaコンテナでターミナルを開き、nvidia-smiと入力してNVIDIA GPUが検出されるか確認してください。
こんにちは、
ありがとうございます。私が言いたかった「Docker: Container Station + CLI 」とは、以下の両方をテストしたという意味です。
QNAP Container Station から作成したコンテナ
Docker CLI で手動起動したコンテナ
また、補足ですが:
nvidia-smi は QNAP シェルのネイティブコマンドとしては存在しません
これからご提案いただいた最小限の Container Station セットアップをテストし、以下を確認します。
コンテナ内での nvidia-smi
Ollama が起動時に引き続き CPU のみを検出するかどうか
元々の問題は、コンテナ内で GPU が認識されていても、Ollama がしばしば以下のように表示することです:
inference compute id=cpu library=cpu
total_vram="0 B"
また、時々以下のようなエラーも発生します:
ggml_cuda_init: failed to initialize CUDA: initialization error
YAML テストの結果は改めてご報告します。
現在、この問題はドライバーのメモリアロケーションバグによっても引き起こされている可能性があると考えています。新しいドライバーを対象としたアップデートを近日中にリリースする予定です。ご不便をおかけして申し訳ございません。
私の場合、再起動するとollama + GPUが使用できるようになります。しかし、GPUがしばらくアイドル状態になると、ollamaではGPUが反応しなくなります。興味深いことに、QTSではGPUが認識され、emby(.qpkgバージョン、Containerバージョンではない)でも使用できるようになります。GPUはContainerに専用割り当てされていて、QTSには割り当てられていないにもかかわらずです。
なぜこのようなことが起こるのでしょうか?
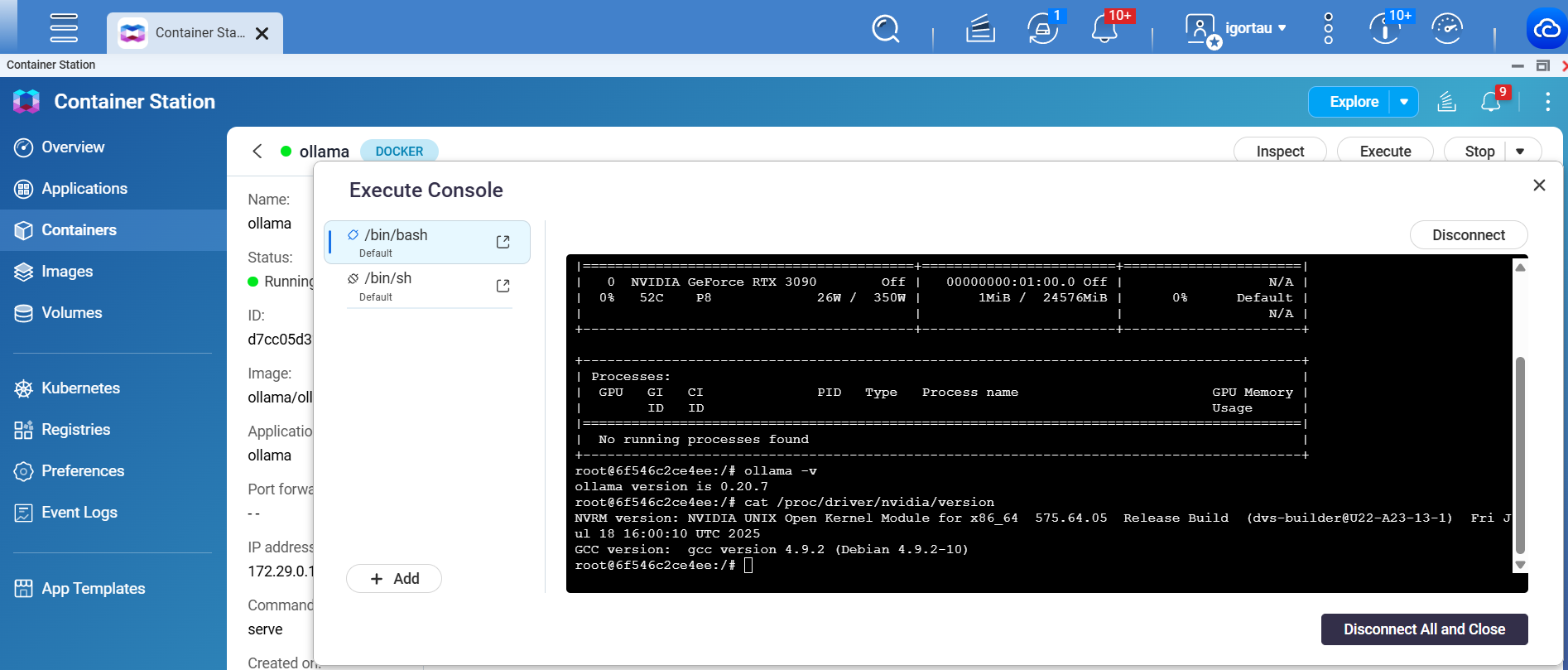
試してみましたが、私もコンテナ内でGPUにアクセスできず、OllamaをGPUで動作させることができません。Ollamaコンソールではnvidia-smiも動作します。Igorgogiと同じセットアップです。しかし、OllamaはGPUから利用可能なVRAMを取得できず、そのためCPUを使用することを選択します。非常に小さなLLMモデルが選択されています。利用可能なVRAM: 12GB
±----------------------------------------------------------------------------------------+
±----------------------------------------------------------------------------------------+
Ollamaログ:
\u001b\]11;?\u001b\\time=2026-04-18T14:24:46.098Z level=INFO source=routes.go:1752 msg=“server config” env=“map\[CUDA_VISIBLE_DEVICES: GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:0 OLLAMA_DEBUG:INFO OLLAMA_DEBUG_LOG_REQUESTS:false OLLAMA_EDITOR: OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:xxx OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY:cuda OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NO_CLOUD:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:xxx app://\* file://\* tauri://\* vscode-webview://\* vscode-file://\*\] OLLAMA_REMOTES:\[ollama.com \] OLLAMA_SCHED_SPREAD:true OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:\]”
time=2026-04-18T14:24:46.103Z level=INFO source=types.go:60 msg=“inference compute” id=cpu library=cpu compute=“” name=cpu description=cpu libdirs=ollama driver=“” pci_id=“” type=“” total=“31.3 GiB” available=“25.7 GiB”
time=2026-04-18T14:24:46.102Z level=INFO source=routes.go:1810 msg=“Listening on \[::\]:11434 (version 0.20.7)”
time=2026-04-18T14:24:46.102Z level=INFO source=images.go:506 msg=“total unused blobs removed: 0”
time=2026-04-18T14:24:46.101Z level=INFO source=images.go:499 msg=“total blobs: 25”
time=2026-04-18T14:24:46.103Z level=INFO source=runner.go:67 msg=“discovering available GPUs…”
time=2026-04-18T14:24:46.103Z level=INFO source=routes.go:1860 msg=“vram-based default context” total_vram=“0 B” default_num_ctx=4096
xBenny
2026 年 5 月 4 日午後 6:33
8
こんにちは、私もQNAPで非常によく似た問題を確認しています — 同じドライバー、同じQTS、GPUだけ異なります。
私の構成:
NAS: QNAP TS-673A - 32GB RAM
GPU: RTX 3050 OC Low Profile 6G (GA107)
QTS: 5.2.9 / カーネル: 5.10.60-qnap
NVIDIAドライバー: 575.64.05(Open Kernel Module)
CUDA: 12.9
DockerはContainer Station経由で、runtime: nvidia-runtime
GPUを利用しているコンテナ:
Jellyfin — NVENCハードウェアトランスコーディング
go-vod — Nextcloud Memoriesの動画処理用NVENC
どちらのコンテナもruntime: nvidia-runtimeを使用し、NVIDIA_VISIBLE_DEVICESにGPUのUUID、NVIDIA_DRIVER_CAPABILITIES=compute,video,utilityを設定しています。privileged: trueや手動でのデバイスマウントはしていません — nvidia-runtimeが自動的に処理してくれます。
正常に動作すること(少なくとも最初は):
ホストおよびコンテナ内でのnvidia-smi ✓
JellyfinでのNVENCハードウェアエンコード ✓
Nextcloud Memories用go-vodでのNVENC ✓
一定期間使用しないと、CUDAの初期化がすべてのGPUコンテナで同時に失敗します — Jellyfinとgo-vodが同時に動かなくなります。唯一確実な対処法はNAS本体の再起動のみです。コンテナの再起動では解決しません。
自分で調べてできることはすべて試しました:
nvidia-smi -pm 1(パーシステンスモード) — 効果なしprivileged: true — 起動時に問題発生手動デバイスマウント — 効果なし
docker.jsonでcgroupfsドライバー — 若干改善
QNAPにはサポートチケットを1か月近く前から出していますが、返事は「対応中」とだけで — ETAもワークアラウンドも具体的な情報もありません。複数のユーザーが、GPUが異なっても複数のフォーラムスレッドで再現している明確な問題なのに、本当にフラストレーションが溜まります。
QNAPによるドライバー回避策がリリースされるまでの一時的な解決策
私も同じ問題で本当に頭を抱えていました!OllamaとOpen WebUIをContainer Stationで稼働させていて、RTX 3060 12GB GPUをパススルーしていました。最初の使用後、Ollamaがアイドル状態になるたびにGPUはnvidia-smiで利用可能と表示されているにもかかわらず自動的にCPUに切り替わり、コンテナの再起動なしではGPUを再び使えるようにする方法がありませんでした。
最終的に、OllamaをNVMeに移したところ、すべてが見違えるほどスムーズに動作するようになりました。モデルの切り替えも素早く、新しいモデルがGPUに即座にロードされて、ほぼ瞬時に結果が得られます。OllamaがアイドルになるとGPUは通常通りオフになり、チャットを始めるとすぐにGPUが起動し、すぐに動作します。私の経験上、OllamaをNASのHDD(Ironwolf)にインストールしていると、GPUには遅すぎてCPUに自動的に切り替わってしまっていたようです。
ひとまず他の方の参考になれば幸いです!
こんにちは、
私も同じ問題があります(RTX Pro 4000 Blackwell を使用)。Qsirch の RAG であれ、Ollama コンテナ内であれ、同様です。よく発生しますが、不定期で(毎回同じ待機時間後に起きるわけではありません)、モデルがGPUではなくCPUを使用することがあります。私もサポートチケットを開きました(返答待ちです)。
ここ数日で Ollama を触り始めて、いくつかの基本的な操作は分かってきましたが、問題の原因がどこにあるのかはつかめていません。
私の環境では、すべてのアプリケーション、コンテナ、モデルはRAID SSD上にあります。
xBenny
2026 年 5 月 10 日午後 9:42
11
自分は常にSSD上でコンテナを使っているので、この方法は自分には当てはまりません。1か月前からチケットを開いていますが、今のところ「対応中です」という返答しかもらえていません。追加の情報も入力しましたが、それ以降返事がありません。
xBenny
2026 年 5 月 11 日午後 5:42
13
7.5.からの回答は以下の通りです……
こんにちは
ご返信ありがとうございます。お手数をおかけしますが、この問題について弊社開発チームが対応するまで少々お時間をいただきます。
現在も開発チームが対応中です。
進展があり次第、すぐにご連絡いたします。ありがとうございます。
1月頃に、Nvidiaドライバーの手動再インストールが必要になったファームウェアアップデート以降、私も同じ問題が発生しています。問題解決のためのログなど追加リソースを提供できるよう、Q-202606-32810を開きました。CUDAからフォールバックして100%CPU使用率になるせいで、ワークフローに支障が出始めています。
QuTS Hero 6.0へのアップグレード(およびそれに付随するNvKernelドライバのアップデート)で問題が解決したことを確認できます。作業していた方々は、約200万件のアセットをOCRで処理し、その後プロセスを停止してGPUをアイドル状態にし、モデルを切り替えてから他のワークロードも週末中に問題なく実行できました。今朝、約18時間ぶりにジョブが再開されましたが、これまで発生していたGPUエラーもなく、モデルも問題なくロードされました。
残念ながら、私の場合、最初の投稿時には既にQuTS Hero 6のベータ版を使っていて、最新のドライバーも入っていましたが、正式版への移行でも何も変わりませんでした。GPUからCPUへの切り替えが常に発生します。ただ、「多少マシ」になった気がしていますが、これはモデル側のメモリオーバーフローによるものかもしれません。今後数日しっかり監視していきます。
xBenny
2026 年 6 月 8 日午後 6:21
17
答えが分かりましたので、下をご覧ください。最初にそれを試しましたが、効果はないようでした。NASを再起動しましたが、状況はさらに悪化し、システムがグラフィックカードを使えなくなりました。その後、NvKernelDriverを再インストールしたところ、すべて動作し始めました。今のところ5時間問題なく動いています。明日の朝どうなるか見てみます…
こんにちは
開発チームから一時的な回避策が提供されています。
SSH経由でNASにアクセスし、以下のコマンドラインを試してください:
# sync; echo 3 > /proc/sys/vm/drop_caches
その後、アプリケーションを再起動してください。問題が解消しない場合は、システムを完全に再起動すると解決するはずです。
ありがとうございます。
xBenny
2026 年 6 月 9 日午前 10:49
18
数時間後にまた問題が再発したので、これは一時的な解決策にすらなっていません。
 私の環境
私の環境 動作していること
動作していること 動作しないこと
動作しないこと 試したこと
試したこと 現時点での理解
現時点での理解 質問
質問 回避策
回避策