大家好,
我正在嘗試在我的 QNAP NAS 上,透過 Docker 以 GPU 加速方式運行 Ollama,但它總是回退到 CPU。我已經進行了不少除錯,如果有人能提供建議或確認這是不是已知限制,將不勝感激。
 我的環境
我的環境
-
QTS:5.2.9
-
核心:5.10.60-qnap
-
GPU:NVIDIA GeForce RTX 3090
-
NVIDIA 驅動(QPKG):575.64.05
-
驅動類型:NVIDIA Open Kernel Module(開源核心模組)
-
Docker:Container Station + CLI(--gpus all)
 正常運作的部分
正常運作的部分
nvidia
nvidia_uvm
nvidia_modeset
nvidia_drm
所以 GPU passthrough(直通)到容器看起來沒問題。
 無法運作的部分
無法運作的部分
Ollama 無法偵測到 GPU,始終使用 CPU:
inference compute id=cpu library=cpu
total_vram="0 B"
即使 GPU 可用。
 測試過的項目
測試過的項目
1. 不同 Ollama 版本
-
0.20.6-rc1
-
0.20.5
-
0.19.0
→ 結果相同(僅用 CPU)
2. CUDA 函式庫
容器內 CUDA 函式庫存在:
/usr/lib/ollama/cuda_v12/libcudart.so.12
/usr/lib/ollama/cuda_v12/libcublas.so.12
/usr/lib/ollama/cuda_v12/libcublasLt.so.12
一開始 ldd 顯示有缺少函式庫,但設定:
LD_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/cuda_v12:/usr/lib/x86_64-linux-gnu
→ 所有依賴都能正確解析。
3. 仍然失敗
儘管如此,Ollama 在 CUDA 初始化時失敗:
ggml_cuda_init: failed to initialize CUDA: initialization error
4. 核心日誌(這看起來很可疑)
NVRM: nvCheckOkFailedNoLog: Check failed: Out of memory [NV_ERR_NO_MEMORY]
NVRM: faultbufCtrlCmdMmuFaultBufferRegisterNonReplayBuf_IMPL: Error allocating client shadow fault buffer
 我的目前理解
我的目前理解
看起來:
由於我用的是 NVIDIA Open Kernel Module(開源核心模組),我懷疑:
 它可能在這個環境下不完全支援 CUDA 工作負載
它可能在這個環境下不完全支援 CUDA 工作負載
或是 QNAP 核心(5.10.60)有相容性問題
 問題
問題
-
有沒有人成功在 QNAP 上用 GPU 跑過 Ollama(或其他 CUDA 密集型應用)?
-
這是 NVIDIA Open Kernel Module 在 QNAP 上的已知限制嗎?
-
有沒有可能改用 NVIDIA 專有驅動程式(proprietary driver) 取代開源模組?
-
有人遇過像這樣的 NV_ERR_NO_MEMORY 錯誤嗎?
 臨時解法
臨時解法
目前我考慮:
如果你正在使用 Docker Compose 文件,請在 ollama 部分加入以下內容。
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
你好,你的意思是:
Docker:Container Station + CLI
nvidia-smi 在主機上運作(透過容器)
===
請按照以下步驟檢查你的問題:
-
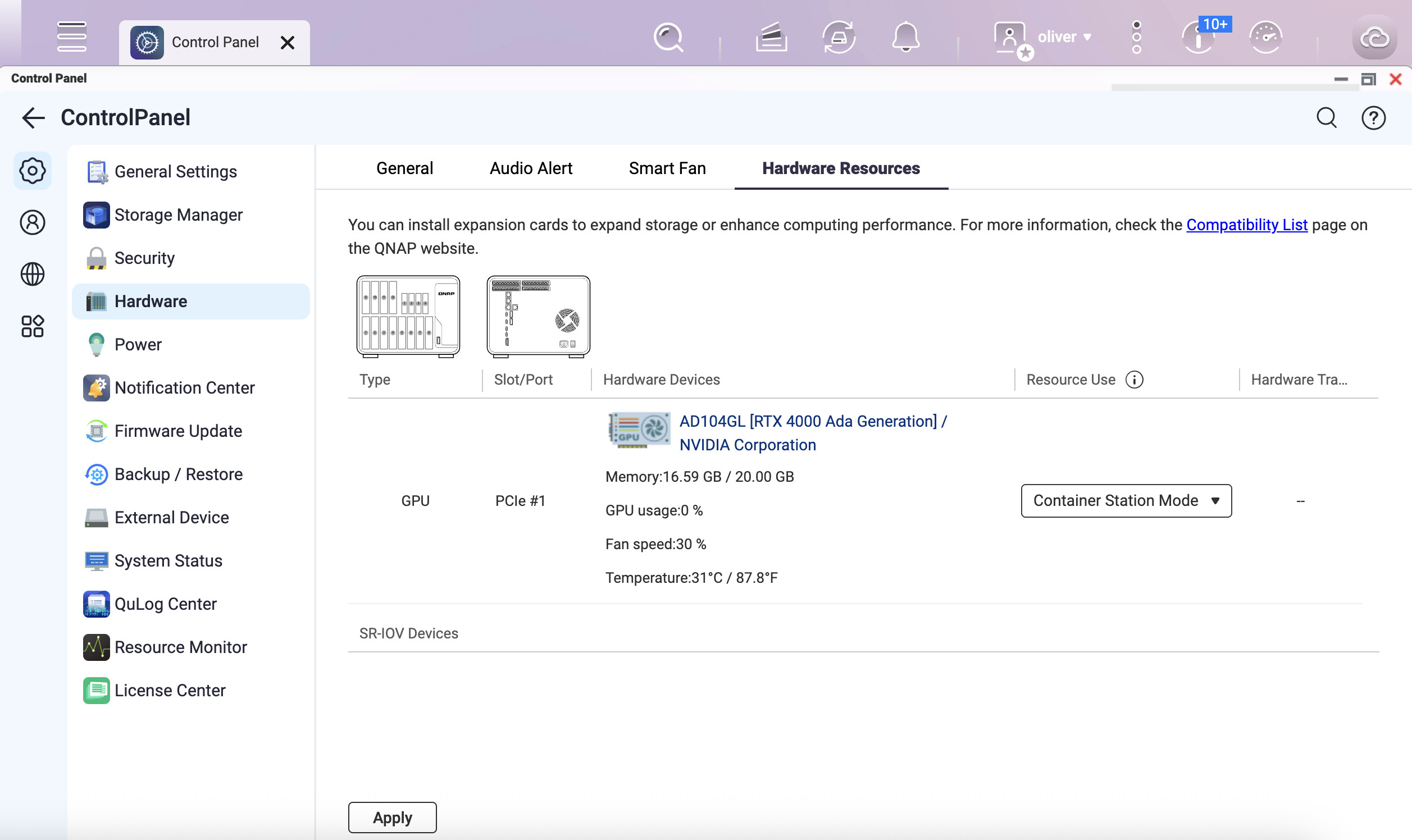
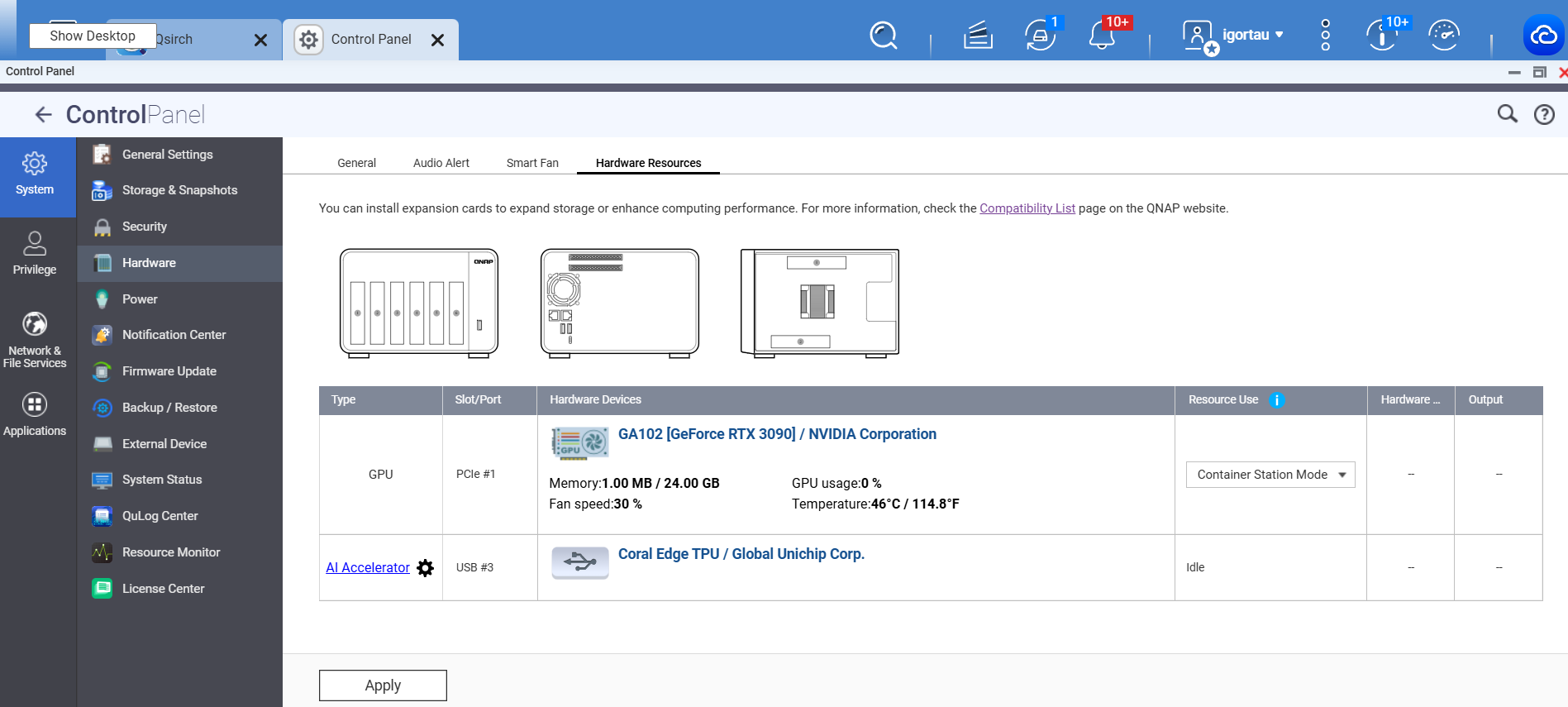
在控制面板中截取 GPU 設定。
-
使用以下 YAML 檔案在 Container Station 中建立一個新應用程式。
services:
ollama:
image: ollama/ollama:latest
volumes:
- ollama:/root/.ollama
restart: unless-stopped
environment:
- OLLAMA_SCHED_SPREAD=1
ports:
- 11434:11434
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
ollama:
-
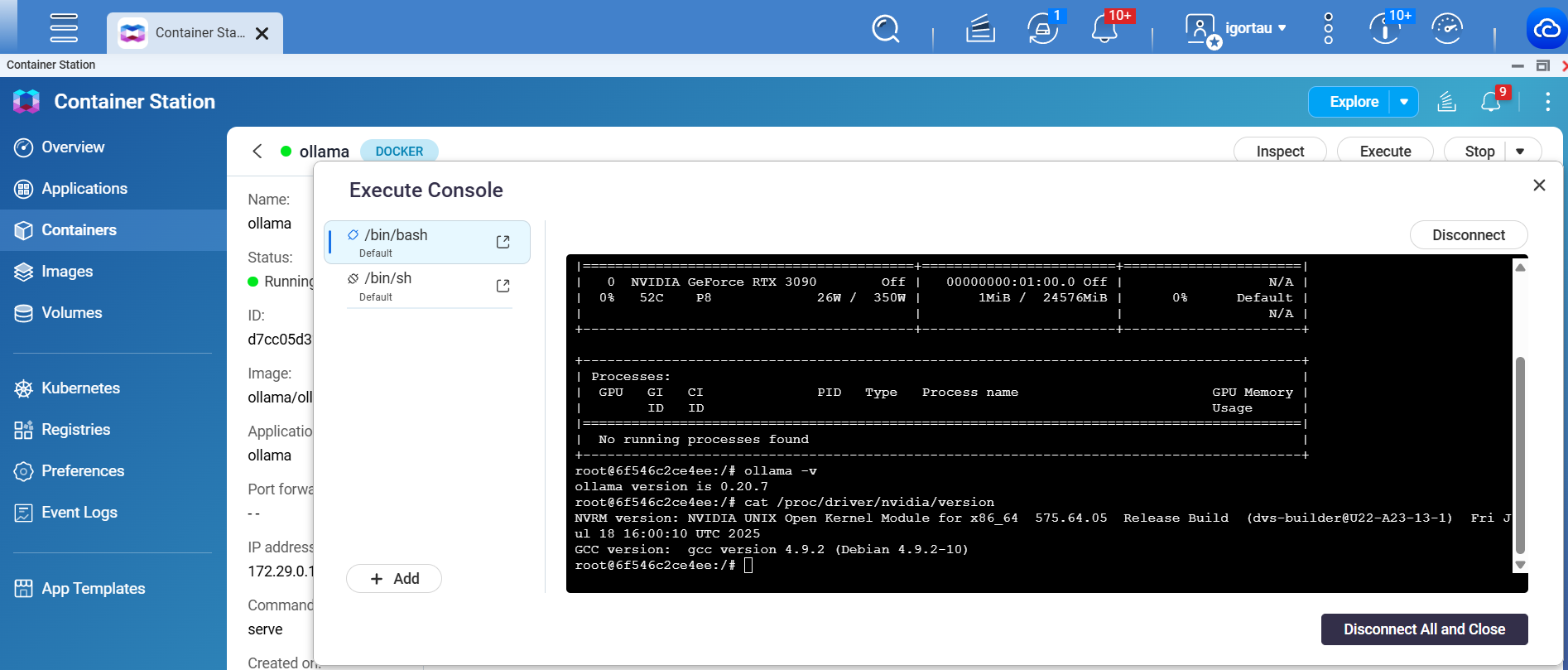
在新的 Ollama 容器中開啟終端機,輸入 nvidia-smi 以檢查是否能偵測到 NVIDIA GPU。
您好,
謝謝。關於:
「Docker:Container Station + CLI」
我的意思是我測試了兩種情況:
另外,說明一下:
nvidia-smi 並不是 QNAP shell 的原生指令,
但在有 GPU 存取權限的 Docker 容器內可以正常運作。
我現在會測試您建議的最小 Container Station 設定,並檢查:
-
容器內的 nvidia-smi
-
Ollama 啟動時是否仍然只偵測到 CPU
我原本的問題是,即使在容器內可以看到 GPU,Ollama 經常回報:
inference compute id=cpu library=cpu
total_vram="0 B"
有時則會出現:
ggml_cuda_init: failed to initialize CUDA: initialization error
我會回報您的 YAML 測試結果。
我們目前懷疑此問題也可能是由驅動程式中的記憶體分配錯誤所引起。我們將針對新驅動程式發布相應的更新。對於由此造成的不便,我們深感抱歉!
對我來說,看起來當我重啟後,ollama + GPU 可以正常使用。但經過一段 GPU 空閒時間後,GPU 在 ollama 裡就無法回應了。有趣的是,這時 GPU 在 QTS 裡變得可見,而且 emby(.qpkg 版本,不是 Container 版本)也能使用它。儘管 GPU 是專門分配給 Container 而不是 QTS 的。
這是怎麼回事?
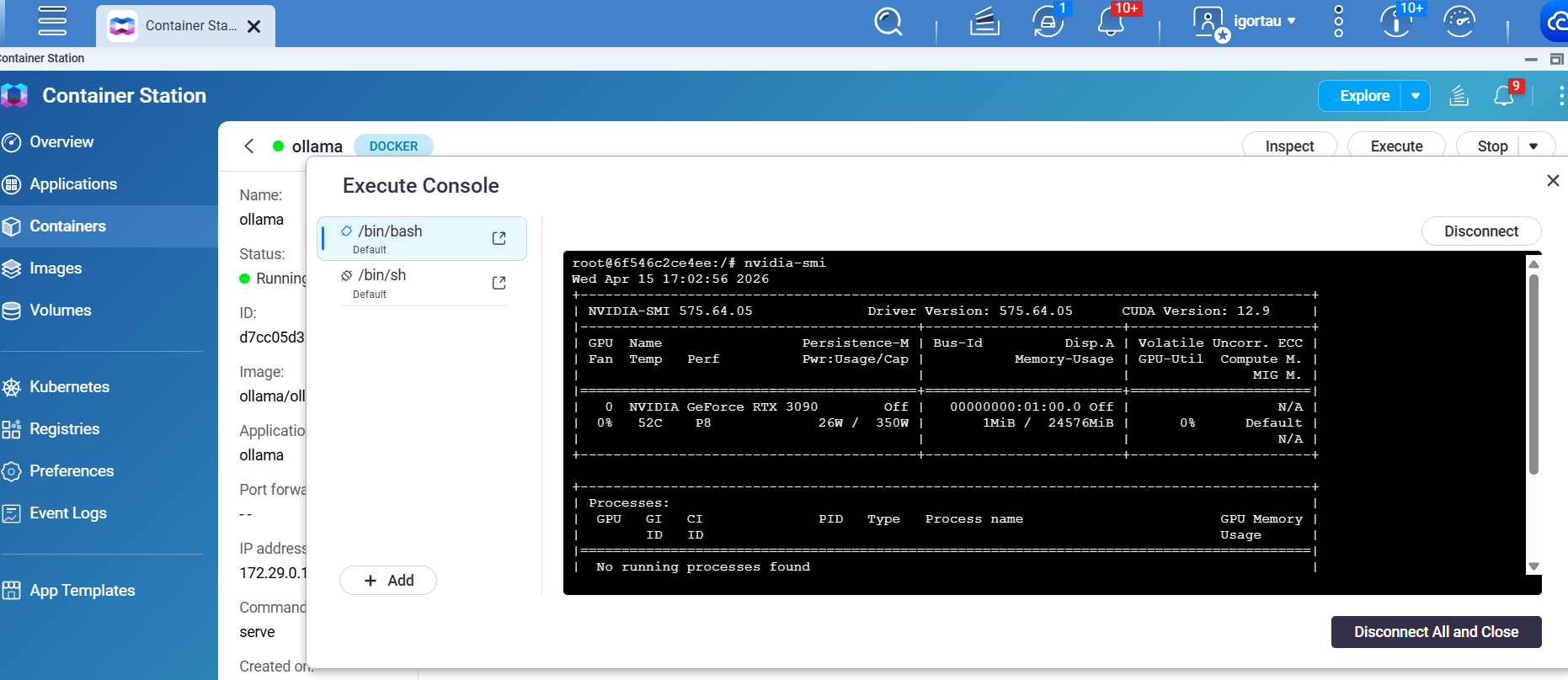
嘗試後,我也無法在 Container(容器)中存取 GPU,導致無法讓 Ollama 使用 GPU。即使在 Ollama 控制台中 nvidia-smi 可以運作。與 Igorgogi 的設定完全相同。但 Ollama 無法從 GPU 取得可用 VRAM,因此決定使用 CPU。選擇的 LLM 模型非常小。可用 VRAM:12GB
±----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.64.05 Driver Version: 575.64.05 CUDA Version: 12.9 |
|-----------------------------------------±-----------------------±---------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX A2000 12GB Off | 00000000:01:00.0 Off | Off |
| 30% 46C P8 13W / 70W | 1MiB / 12282MiB | 0% Default |
| | | N/A |
±----------------------------------------±-----------------------±---------------------+
±----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
±----------------------------------------------------------------------------------------+
Ollama 日誌:
\033]11;?\033\time=2026-04-18T14:24:46.098Z level=INFO source=routes.go:1752 msg=“server config” env=“map[CUDA_VISIBLE_DEVICES: GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:0 OLLAMA_DEBUG:INFO OLLAMA_DEBUG_LOG_REQUESTS:false OLLAMA_EDITOR: OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:xxx OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY:cuda OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NO_CLOUD:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:xxx app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_REMOTES:[ollama.com] OLLAMA_SCHED_SPREAD:true OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]”
time=2026-04-18T14:24:46.103Z level=INFO source=types.go:60 msg=“inference compute” id=cpu library=cpu compute=“” name=cpu description=cpu libdirs=ollama driver=“” pci_id=“” type=“” total=“31.3 GiB” available=“25.7 GiB”
time=2026-04-18T14:24:46.102Z level=INFO source=routes.go:1810 msg=“Listening on [::]:11434 (version 0.20.7)”
time=2026-04-18T14:24:46.102Z level=INFO source=images.go:506 msg=“total unused blobs removed: 0”
time=2026-04-18T14:24:46.101Z level=INFO source=images.go:499 msg=“total blobs: 25”
time=2026-04-18T14:24:46.103Z level=INFO source=runner.go:67 msg=“discovering available GPUs…”
time=2026-04-18T14:24:46.103Z level=INFO source=routes.go:1860 msg=“vram-based default context” total_vram=“0 B” default_num_ctx=4096