Have you ever experienced something like, “When using a NAS, it takes a long time to open a folder with a large number of files in it”?
The information such as “what files are where and what attributes they have” is also stored on the NAS, and when you open a NAS folder from the client’s Explorer, the metadata such as the file list in the folder and their basic attributes (like creation date) are retrieved from the NAS. When the number of files increases, the amount of information such as file names and metadata becomes large, so it takes time to complete the retrieval, resulting in slower display in Explorer.
This time, a customer asked, “How long does it take to open a folder when a large number of files are saved in one folder?” So, I experimented while considering how to obtain measurable numbers that could serve as an indicator.
Experimental Environment
TS-h1290FX
CPU: AMD EPYC™ 7302P 16-core/32-thread processor, up to 3.3 GHz
Memory: 64GB (reduced from the default 128GB for certain reasons)
Storage: Samsung MZQLB960HAJR-00007 x4
RAID configuration: RAID5
OS: QuTS hero h5.3.0.3066
Note: HA configuration with 2 TS-h1290FX units
Connected to the Windows client HP Z8 G4 via 10GbE SFP+.
Note: During High Availability testing, a cluster is configured with two TS-h1290FX units, but I believe this does not affect read speed.
Experimental Method
A large number of files are created in a NAS folder, and the time taken to complete reading is measured using several methods.
Although this is not the actual operation of opening from Explorer, I think the trend can be observed.
Script used to generate a large number of files
#!/bin/sh
#FILESIZE in MB
FILESIZE=1
if [ "${1}" = "" ] ; then
exit 1
else
NumFiles=$1
fi
for i in `seq 1 ${NumFiles}`
do
echo ${i}
filename=`printf testfile.%08d ${i}`
if [ -f "${filename}" ] ; then
echo "skip ${filename}"
else
:
dd if=/dev/zero of=${filename} bs=1M count=${FILESIZE}
fi
done
This creates as many files as specified, each 1MB in size.
The key factor is the “number of files,” not the “file size,” so small files are generated here.
How to measure the time taken to read the file list
Method using find
time find ./ > /dev/null
By discarding the output to /dev/null, the measured time is purely the time required to traverse the files.
Method using ls -la
time ls -la > /dev/null
Similarly, the output is discarded to /dev/null.
Method using dir from a Windows client
echo |time
dir > nul 2>&1
echo |time
The elapsed time is measured by the difference in the output of the time command.
Among the measured numbers, I think this result is the closest to the time required when opening a folder from Explorer.
That said, this number:
- Includes the time for network processing when retrieving the NAS file list via the SMB protocol.
- Since the connection between the client PC and NAS is 10GbE, there is a possibility that network bandwidth is the bottleneck.
- Does not include the speed of rendering-related processing required for display in Explorer.
- When displaying in Explorer, the file list is probably buffered in memory, but does not include the time required to allocate enough memory to store the file list.
So, if the client PC is low on memory and needs to use swap, etc., to prepare space for the file list, naturally the time it takes to display in Explorer will increase significantly, but please understand that such client-side circumstances are not considered in these numbers.
Measurement Results
Below are the measurement results. (The “speed” refers to the “number of seconds” until processing is complete.)
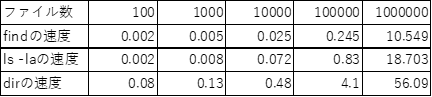
For the internal processing, “find” and “ls -la” each completed processing in about 10 seconds and just under 20 seconds, respectively, with 1,000,000 files. Since “find” only retrieves file names, while “ls -la” also retrieves information such as permissions, the latter is heavier and takes more time.
For “dir,” it took just under 1 minute for 1,000,000 files. If the amount of metadata per file is about the same as with “ls -la” (though it may also retrieve ACLs…), this difference can be attributed to the SMB protocol overhead.
Since a lot of time is spent on round trips over the network, enabling jumbo frames or using faster connection methods like 25G or 100G may shorten this time.
For now, please take this as a reference.
Summary
I used the “dir” command from a Windows client to quantitatively observe the phenomenon where Explorer’s response worsens as the number of files in a folder increases.
With 1,000,000 files, it took just under 1 minute to retrieve the entire file list, so I think it’s best to design the folder structure with a maximum of about 100,000 to 200,000 files per folder.
Also, since these results are from the all-flash model TS-h1290FX, the results may differ with entry models like the TS-464. However, even in that case, I think 100,000 files per folder is a good guideline.
I hope this is helpful.
If you measure in your own environment and get results, I’d appreciate it if you could share them with the community.